HTTP 的发展
- 1991:http/0.9
- 1996: http/1.0
- 1999: http/1.1
- 2015: http/2
HTTP1.0
HTTP1.0 最大的一个特点就是:无连接
HTTP1.0浏览器与服务器只保持短暂的连接,每次请求都需要建立一个TCP连接。服务器响应完成,得到客户端的确认之后就立即断开。
无连接带来的一个缺点:假如解析HTML文件的时候发现里面嵌入了很多资源文件,如图片,视频,音频等。这时候又需要创建单独的连接。这就导致了一个HTML文件的访问包含了很多的次的请求和响应。这种形式很明显的就造成了性能上的一个缺陷。
HTTP1.0如果需要建立长连接,需要设置非标准的字段Connection:keep-alive`。
HTTP1.1
持久连接
HTTP1.1默认是长连接(Connection: keep-alive);即在一个TCP连接上可以传送多个HTTP请求和响应,这样就减少建立和关闭连接的消耗和延迟。
如果客户端和服务端发现对方一段时间没有活动,就可以主动关闭连接。不过规范的做法是:客户端在请求最后一个请求的时,发送Connection:close,明确服务器关闭TCP连接。
管道机制(pipelining)
HTTP1.1引入了管道机制;即在同一个TCP连接中,客户端可以同时发送多个请求,这样就增加了效率。只不过服务器还是得按顺序来返回响应,客户端才能区分出来。
举个例子:客户端需要请求两个资源。以前的做法是,在同一个TCP连接里, 先发送A请求。然后等待服务器的响应,收到响应之后再发出B 请求。而管道机制允许浏览器同时发出这两个请求,但是服务器还是得按照顺序来响应。
缓存机制
HTTP1.0中主要是使用 header头部的 Last-Modified/If-Modified-Since, Expires来作为缓存判断的标准,HTTP1.1引入了更多的缓存控制策略,比如:Etag/If-None-Match,If-Unmodified-Since ,If-Match等更多的可供选择的缓存头来控制缓存策略。
关于 缓存机制可以看这篇文章:前端浏览器缓存
HOST头处理
在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此请求消息中并没有传递主机名,但是随着虚拟主机技术的发展,在一台物理服务器上可以存在更多的虚拟主机,他们共享这一个IP地址。
所以HTTP1.1在请求头都加上HOST。 表示指定请求的服务器的域名和端口号。如果请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
引入range
在HTTP1.0中, 如果客户端值需要某个对象的一部分,但是服务器却将整个对象发送过来了,即不支持断点续传功能,
在HTTP1.1中请求头部引入了 range头域,允许只请求资源的某个部分。返回状态码为 206。使用的场景: 断点续传。
断点续传
从下载断开的位置继续下载,直到下载完成。
1 | Range: <unit>=<range-start>- |
范围所采用的单位,通常是字节(bytes)。
一个整数,表示在特定单位下,范围的起始值。
一个整数,表示在特定单位下,范围的结束值。这个值是可选的,如果不存在,表示此范围一直延伸到文档结束。
举个例子:
1 | Range: bytes=200-1000 |
表示请求的范围:起始字节为200, 结束字节为1000的内容。
与范围相关的三种状态:
- 请求成功:服务器会返回206(Partial Content)状态码。
- 请求范围越界:服务器会返回416(
Requested Range Not Satisfiable)(请求的范围无法满足) 状态码 - 不支持范围请求: 服务器返回 200 状态码, 将整个文件对象返回
Content-range:用于响应头,描述响应覆盖的一个内容范围和整个实体的长度;
1 | Content-Range: bytes (unit first byte pos) - [last byte pos]/[entity legth] |
举个例子:
请求下载:
1 | GET /test.rar HTTP/1.1 |
一般正常回应:
1 | 200 OK |
添加了其他的请求方法:
PUT,DELETE,OPTIONS,HEADE,PATCHD等
HTTP 2
2015 年 HTTP/2版本发布,它不叫HTTP/2.0, 因为标准委员会不打算再发布子版本了。下一个新版本将是HTTP/3.0。
而HTTP/2相比于之前的版本,性能上有很大的提升,添加了很多的特性
二进制分帧
帧:是HTTP/2通信的最小单位。
HTTP/2在应用层和传输成职期间加了一个二进制分帧层。将所有传输的信息分割成更小的消息和帧,并对他们采用二进制格式编码,其中HTTP1.x中的头信息会被封装到header帧,body封装到data帧;然后HTTP/2的通信都是在一个TCP连接上完成的(我请求一个页面http://www.qq.com。页面上所有的资源请求都是客户端与服务器上的一条TCP上请求和响应的!)。这个连接可以承载任意数量的双向数据流,因此每个数据以消息的形式发送,而消息是由一个或者多个帧组成;这些帧是可以乱序发送的。然后根据每个帧的首部的顺序标识符来重新组装。
多路复用
HTTP/2复用TCP连接,在一个连接里面,客户端和服务端都可以同时发送多个请求或响应。而且不用按照顺序来一一对应。这样就避免了”队头堵塞”。
多路复用主要用来解决两个问题:
解决第一个问题:在
HTTP1.1协议中, 我们传输的request和response都是基于文本格式的,这样就会引发一个问题, 就是所有的数据必须是按着顺序来发送的,比如需要传输:hello world,只能从h到d一个一个的传输,不能并行传输,因为接收端并不知道这些字符的顺序,所以并行传输在HTTP1.1是不能实现的。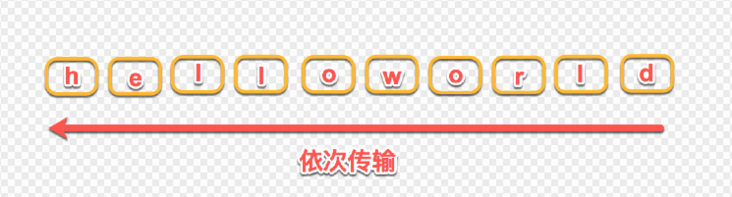
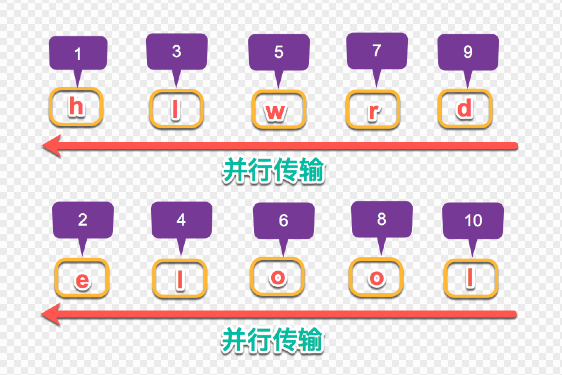
HTTP/2引入二进制数据帧和流的概念,其中帧对数据进行顺序标识,如下图所示,这样浏览器收到数据之后,就可以按照序列对数据进行合并,而不会出现合并后数据错乱的情况。同样是因为有了序列,服务器就可以并行的传输数据,这就是流所做的事情。
- 解决第二个问题:
HTTP/2对同一域名下所有请求都是基于流,也就是说同一域名不管访问多少文件,也只建立一路连接。同样Apache的最大连接数为300,因为有了这个新特性,最大的并发就可以提升到300,比原来提升了6倍!
举例来说:在一个TCP连接中,服务器同时收到A,B请求,于是先处理A请求,结果发现A 请求处理过程非常耗时,于是先发送A请求已经处理好的部分,接着处理B请求,完后才能后,在发送A请求剩下的部分。
首部压缩
HTTP 2.0 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送;通信期间几乎不会改变的通用键-值对(用户代理、可接受的媒体类型,等等)只 需发送一次。事实上,如果请求中不包含首部(例如对同一资源的轮询请求),那么 首部开销就是零字节。此时所有首部都自动使用之前请求发送的首部。
如果首部发生变化了,那么只需要发送变化了数据在Headers帧里面,新增或修改的首部帧会被追加到“首部表”。首部表在 HTTP 2.0 的连接存续期内始终存在,由客户端和服务器共同渐进地更新 。
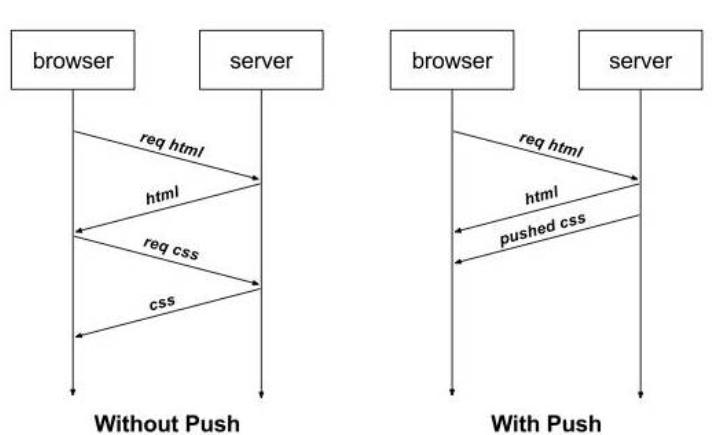
服务器推送
HTTP 2.0 引入了服务器推送,允许服务端推送资源给客户端。
服务器会顺便把一些客户端需要的资源一起推送到客户端,如在响应一个页面请求中,就可以随同页面的其它资源
免得客户端再次创建连接发送请求到服务器端获取
这种方式非常合适加载静态资源